1. Latency Is Becoming the New Intelligence
Since the rise of LLM serving, the bottleneck of inference systems has shifted several times.
At first, the challenge was simply getting large models to run at all. Later, the industry moved toward throughput-first optimization: larger batches, deeper queues, continuous batching, and increasingly sophisticated KV-cache hierarchies gradually became the dominant design center of inference systems.
But real-time AI interaction is changing that assumption.
ChatGPT
Cursor · Claude Code · Codex
factories · agents · finance · vehicles
Agents, voice interaction, code completion, tool use, and Test-Time Scaling are steadily pushing inference back toward latency-first execution. Users no longer care only about aggregate throughput, but whether the next response arrives fast enough.
As batch sizes shrink, overheads previously hidden behind throughput begin resurfacing: kernel launches, synchronization, runtime scheduling, memory movement, and communication overhead all start re-entering the critical path.
At the same time, Test-Time Scaling is making system speed directly affect model capability itself. Under fixed latency budgets, faster inference enables more rollouts, deeper reasoning paths, and stronger self-verification.
Speed is no longer just a systems metric. It is increasingly becoming part of the reasoning budget itself.
Modern AI systems are therefore starting to behave less like offline compute clusters and more like real-time execution systems.
Most existing inference stacks, however, were never designed around this assumption. Whether traditional runtimes or compiler stacks optimized around individual kernels, most systems still fundamentally assume a throughput-oriented execution model. They amortize overhead effectively when enough requests accumulate, but struggle to translate raw hardware capability into end-to-end responsiveness under real-time workloads.
It is precisely in this context that TileRT emerged.
Today, the ultra-fast GLM-5.1 inference service has officially been deployed on the MaaS platform powered by TileRT. From an experimental prototype to a production system serving real traffic, TileRT represents an attempt to rethink the execution model of large-scale LLM inference itself.
2. The Gap Between Hardware Limits and Real Inference
Today, an 8×H200 NVL server provides nearly 38 TB/s of aggregate memory bandwidth.
For GLM-5.1, the activated parameter footprint during decode is only around 42 GB per token. From a purely theoretical bandwidth perspective, decode throughput could approach 1000 token/s even without MTP enabled.
Yet real systems often deliver only a few dozen token/s.
That is not a small optimization gap. It is an order-of-magnitude execution gap.
At first, we assumed the issue was kernel performance. But profiler traces gradually revealed something more counterintuitive: GPU utilization was not particularly low, theoretical FLOPS looked reasonable, and yet token latency remained stubbornly high.
The GPU was not short on compute. Compute was trapped between execution boundaries.
Runtime Begins Entering the Critical Path
Most inference systems still follow a classic execution abstraction:
graph → operator → kernelModels are decomposed into independent operators, each launched separately, synchronized separately, and responsible for their own memory movement.
This abstraction worked remarkably well during the training era because kernels were large enough for computation to amortize launch latency, synchronization, and scheduling overhead.
Decode changes the timescale.
Under latency-first workloads, kernel lifetimes collapse into the tens-of-microseconds regime. Launch latency, cross-kernel barriers, memory spills, and communication synchronization all begin resurfacing.
Profiler traces increasingly exposed a strange phenomenon: the kernel would finish before the pipeline had even fully “warmed up.”
The GPU repeatedly cycles through:
launch → load → compute → store → synchronizeEvery execution boundary interrupts dataflow, destroys locality, and forces synchronization again.
In many cases, the bottleneck is no longer how fast a GEMM executes, but how quickly the next stage can begin.
Under ultra-low-latency inference, runtime orchestration itself increasingly starts resembling the performance wall.
The problem no longer exists only inside kernels. Increasingly, it exists between kernels.
That realization became the starting point for TileRT.
3. TileRT: Rethinking the Execution Model
One of TileRT’s core observations is simple: once runtime orchestration itself enters the critical path, the answer may no longer be “optimize the runtime harder,” but to rethink the execution model altogether.
Traditional inference systems execute a sequence of short-lived kernels. Execution is repeatedly fragmented by launches, synchronization points, operator boundaries, and memory round-trips.
TileRT explores a different direction: instead of continuously launching kernels, the GPU continuously executes a persistent pipeline.
TileRT statically expands the model into a persistent Engine Kernel ahead of time.
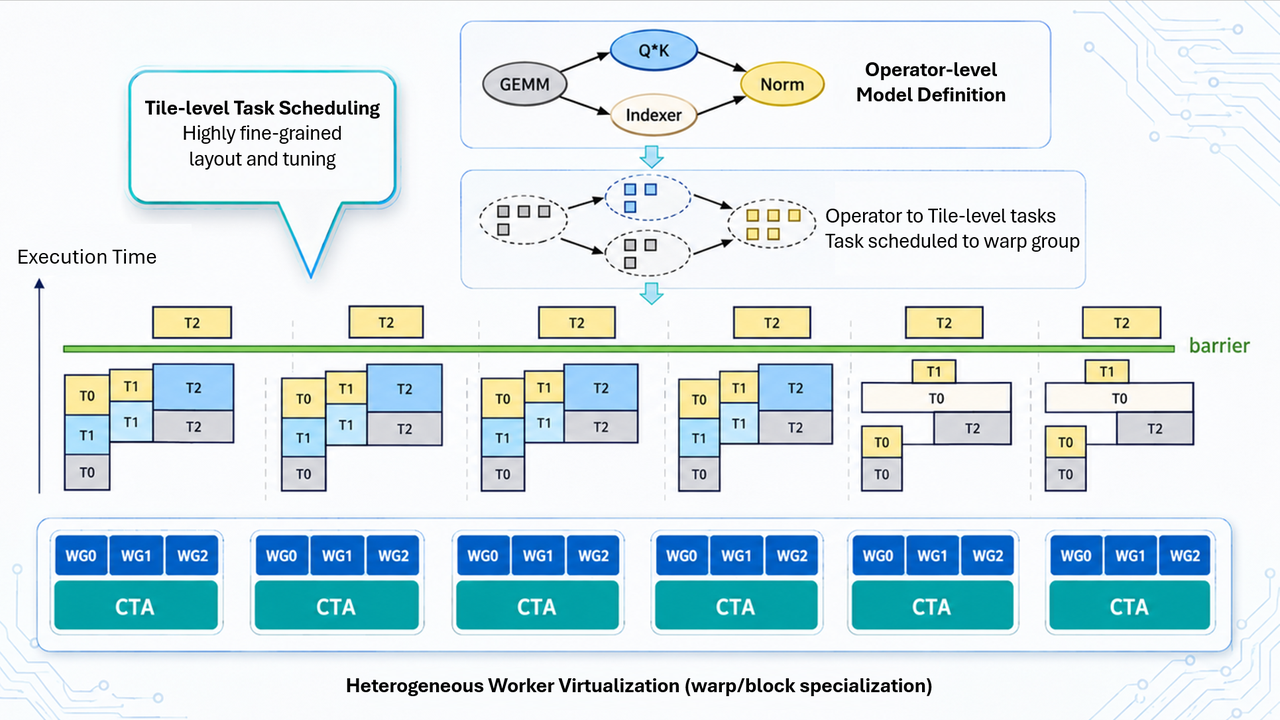
Throughout the decode lifecycle:
- the host launches only once,
- execution remains resident on the GPU,
- much of runtime orchestration moves into compile time.
Traditional systems resemble operator-by-operator scheduling.
TileRT instead reorganizes execution into a tile-level execution pipeline, where compute, communication, and asynchronous IO continuously progress inside the GPU.
To sustain this execution flow, TileRT adopts aggressive Warp / Block Specialization inside the Engine Kernel.
Different warp groups assume different responsibilities:
- asynchronous data movement,
- tensor computation,
- communication overlap.
Previously, many stages progressed serially:
load → barrier → compute → barrierInside TileRT, data movement, tensor computation, and communication increasingly overlap at tile granularity. Intermediate results no longer repeatedly spill back into global memory, but continue flowing forward through registers, shared memory, and L2 cache.
From the profiler’s perspective, the change becomes obvious: the GPU no longer behaves like a device repeatedly launching kernels. It begins behaving more like a persistent execution system.
As decode latency compresses further, many of the largest latency sources turn out not to be computation itself, but idle intervals:
- between kernels,
- between communication and compute,
- between runtime and device execution.
Persistent kernels, tile pipelines, and warp specialization ultimately target the same underlying problem: compressing execution gaps.
As more orchestration logic moves into kernels themselves, inference systems begin taking on a very different form from traditional runtimes.
The runtime no longer continuously “drives” the GPU. Instead, it initializes and maintains a persistent execution flow.
4. From Warp Specialization to Heterogeneous Workers
Persistent execution removes a large portion of the idle gaps inside a single GPU.
But once the system scales across an 8×NVL topology, another boundary begins to emerge: homogeneous parallelism itself.
Most Tensor Parallel frameworks assume that all GPU ranks execute identical logic synchronously.
Inference is beginning to break that assumption.
As sparse routing, Top-K selection, dynamic indexing, long-context attention, and MTP increasingly enter the execution flow, more stages stop fitting naturally into homogeneous scale-out.
Many of these stages are not compute-heavy themselves, but depend heavily on global information and synchronization behavior. Forcing all ranks to execute identical logic introduces redundant computation and synchronization amplification.
Eventually, we began asking a simple question: if warps can specialize, why can’t GPUs?
TileRT therefore extends specialization outward:
warp specialization → block specialization → GPU specializationGPUs are no longer treated as fully symmetric execution units. Different devices assume different responsibilities depending on communication cost, execution density, and data dependencies.
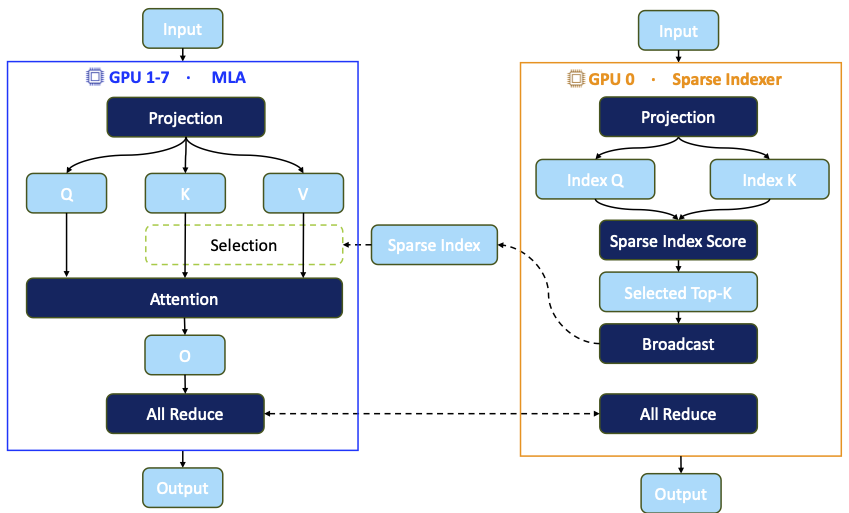
Inside GLM-5.1, the attention layer is decomposed into two types of workers:
- GPU0: Sparse Indexer Worker
- GPU1–7: MLA Workers
The Sparse Indexer handles Top-K selection, sparse index construction, and routing decisions, while MLA Workers execute compute-intensive stages such as RMSNorm, GEMM, Flash Sparse Attention, and AllReduce.
Different execution stages increasingly require different scaling strategies. Some stages are dominated by synchronization and global dependencies, making centralized execution more efficient. Others naturally scale through tensor parallelism.
TileRT no longer forces every stage into the same execution abstraction.
Traditional inference systems still largely treat communication as an external stage.
In TileRT, communication is pushed directly into the execution pipeline itself.
At the host level, an entire attention layer corresponds to only a single Engine Kernel launch. Broadcasts, reductions, and synchronization increasingly execute directly inside the tile-level execution flow.
Execution therefore begins shifting from:
compute → sync → computetoward:
compute ↔ communication ↔ computeas part of a continuously overlapping pipeline.
5. Production-Ready: From Lab Benchmarks to Real Traffic
Extreme benchmarks are often fragile.
The real challenge is not producing impressive numbers inside controlled environments, but sustaining performance near hardware limits under real production traffic.
Production workloads look fundamentally different from benchmarks. Sequence lengths fluctuate, KV caches grow and fragment over time, routing behavior changes across requests, and under MTP workloads, execution paths themselves become dynamic.
As TileRT evolved from prototype into production infrastructure, many optimizations increasingly targeted execution stability rather than peak FLOPS.
In v0.1.1, we further compressed execution gaps and introduced finer-grained overlap inside the Engine Kernel, significantly improving end-to-end latency — especially tail latency.
Later, v0.1.2-alpha.1 introduced MTP into TileRT’s execution flow, bringing dynamic execution paths and new synchronization dependencies.
Once GLM-5 execution paths and ultra-long-context workloads entered production, KV fragmentation, locality degradation, and communication amplification increasingly became dominant constraints.
At that point, the bottleneck was no longer whether a single kernel was fast enough. It was whether execution could remain stable under complex workloads.
As performance approaches hardware boundaries, the hardest problems increasingly stop being GEMM optimization, kernel tuning, or operator fusion.
Inference systems themselves are gradually evolving from collections of operator optimizations into true AI execution infrastructure.
6. The Next Stage: Co-Design
As performance approaches hardware boundaries, many bottlenecks no longer exist inside individual operators.
Increasingly, they emerge from the execution pipeline itself.
Mismatches between model structure, memory hierarchy, communication topology, and execution behavior are beginning to dominate latency-critical workloads.
The next stage of performance gains therefore cannot come purely from runtime optimization alone, but from deeper forms of model-system-hardware co-design.
TileRT is not the endpoint of this direction.
It is better viewed as an attempt to stop thinking about inference systems as “a sequence of launched kernels,” and instead think of them as continuously running execution systems.
As inference increasingly becomes the core execution layer of AI products, speed itself is beginning to enter the scaling equation.
Because inference speed now directly affects:
- reasoning depth,
- interaction quality,
- agent responsiveness,
- real-world productivity.
7. The Speed Is All You Need
If the primary role of GPUs over the past decade was maximizing parallel compute throughput, the next several years may demand something very different: sustaining execution pipelines under extremely tight latency budgets.
That shift will force model architectures, compilers, runtimes, and hardware architectures to evolve together.
Inference speed is no longer merely a systems metric. It increasingly defines the reasoning budget itself.
TileRT is only one step in that direction.
Collaborate With Us
The TileRT team is building and exploring the foundations of high-performance AI systems at the limits of modern hardware.
If you are interested in GPU architecture, compiler optimization, distributed execution, or large-scale inference systems, we would love to talk.
- TileRT GitHub (selected modules open-sourced): github.com/tile-ai/TileRT
- Technical discussion & collaboration: contact@tilert.ai
The speed is all you need.