过去几年,大模型推理系统的优化核心几乎全部围绕 kernel、operator 和 scheduling 展开。大家形成了一种路径依赖:只要 kernel 压榨得足够快、FLOPs 利用率足够高,系统就能无限逼近硬件极限。
这套逻辑在过去很长一段时间里都坚不可摧,因为当时主导系统瓶颈的依然是“纯粹的大计算”。
那些由 launch(启动)、同步、运行时调度以及内存搬运带来的执行开销虽然一直存在,但大多被密集的计算自然掩盖了。然而,当推理真正切入极低延迟的战场时,游戏规则变了。
Agent、代码补全、语音交互以及 Test-Time Scaling,都在强行将系统推向 latency-first(延迟第一)。用户不再满足于吞吐量,而开始对响应速度斤斤计较。当推理速度直接决定了 rollout budget、推理深度与交互质量时,那些曾经被计算掩盖的底层执行开销,瞬间暴露在关键路径上。
在这种背景下,把旗舰模型的性能从几十 TPS 一路飙升到 1000 TPS 时,我们发现:这已经不是简单的量变,而是完全不同的底层优化范式。
几十 TPS 与 1000 TPS,面对的是截然不同的硬件物理现实。
第一次跃迁:Execution Model Revolution
深入底层后我们发现,真正锁死性能的瓶颈,并不在某一个特定的 kernel 跑得不够快,而是整条执行流在微秒级尺度上,被不连续的算子边界所打断。
在传统的推理框架中,模型往往被拆解为大量独立的算子(operator)。每一次 kernel 执行之间,都伴随着 Host 侧的启动延迟、硬件同步以及全局内存往返。在过去“大计算”主导的场景下,这些固定开销还不足以成为核心瓶颈。但当系统走向低延迟、去压榨每一枚 Token 的延迟时,这些原本隐藏在计算背后的开销,开始逐渐显现为明显的 Execution Gap(执行间隙)。
TileRT 的设计初衷,正是为了解决这些由于算子边界带来的执行间隙。
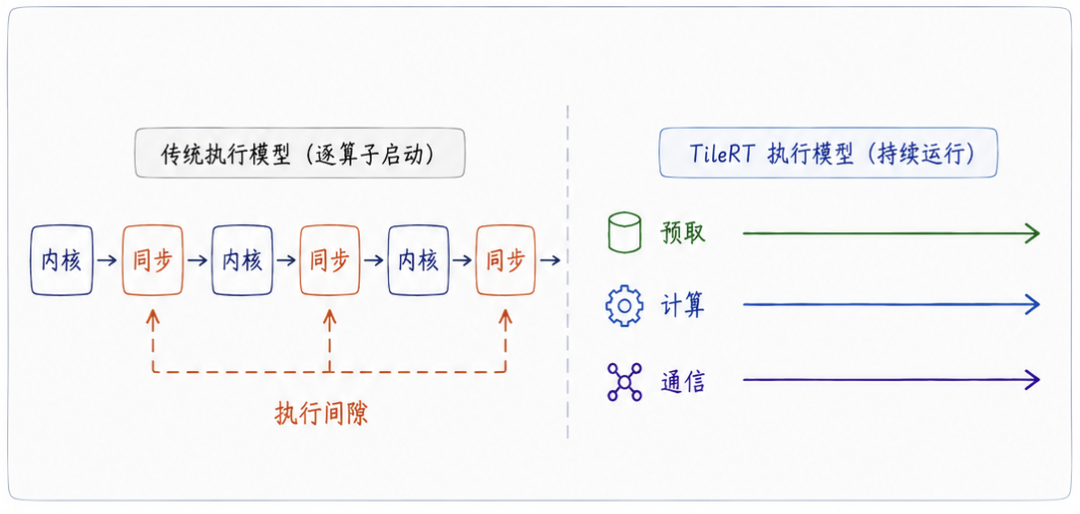
为此,我们尝试引入了一种不同的执行模型:不再让 GPU 采用传统的“逐算子启动”模式,而是让整个计算流水线以常驻内核的形式,在 GPU 内部持续运行。这种常驻模式带来的核心收益,是系统具备了全链路持续预取的能力——当前 Tile 仍在 Compute Core 进行计算时,后续的数据已经开始沿着寄存器、Shared Memory 到 Global Memory 的多级存储架构提前流动。
Tile 级流水线则进一步将数据搬运、张量计算与通信细化为更小粒度的物理 Tile,在芯片内部实现更深度的重叠。
在这个流水线里,Warp Specialization(线程束专业化分工)改变了原有的串行步调,让不同的 Warp 组各司其职、精密协作;而 Heterogeneous Worker(异构工作单元)的引入,则进一步将这种 Specialization 策略,从单个 SM 内部扩展到了整张 GPU 的执行域。
至此,GPU 在原有的同构并行计算设备基础上,进一步演化为一个持续流动、精密协作的异构执行系统。
也正是从这里开始,系统开始跨过旧有执行抽象的边界。从几十 TPS 跨越到大几百 TPS 的这一跃,靠的并不只是某一个独立算子的局部优化,更是执行模型本身发生的一次范式转变。
第二次跃迁:从大几百 TPS 到突破 1000 TPS
——微秒级尺度下的瓶颈拆解与软硬件协同
从几十 TPS 到大几百 TPS,执行模型的重构让我们跨越了第一个数量级边界。对于旗舰模型而言,这本身已经意味着系统正在快速逼近硬件的物理极限。
但真正的工程挑战在于:当系统已经极度接近硬件天花板时,如何进一步实现性能的翻倍?
在这个性能区间内,执行过程中的瓶颈开始以完全不同的方式暴露。
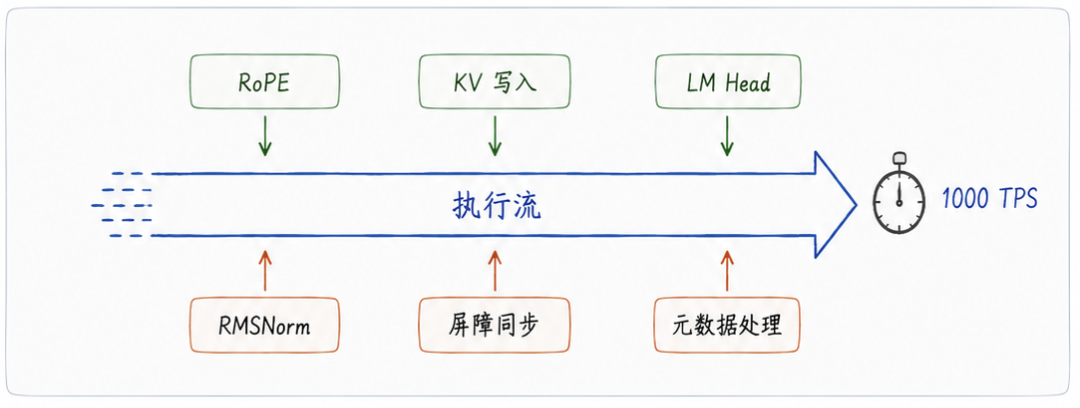
在几十 TPS 的量级时,一个算子(Op)快慢 1 微秒,很多时候不会带来明显的端到端变化,因为主导延迟的仍然是更大粒度的计算与调度。但当系统进入 1000 TPS 的范畴后,单个算子的生命周期被压缩至微秒级。此时,1 微秒的开销都会直接转化为端到端几个百分点的性能抖动。过去很多看似无关紧要的非核心算子,会重新暴露出效率瓶颈。
例如 RMSNorm、RoPE、KV 写入、硬件同步以及元数据搬运。这些操作单独看计算量都不大,但它们在微秒级的节拍里会不断打断执行流,累积成明显的延迟。以 Attention 层为例,限制系统速度的,往往不再是 Attention Kernel 本身,而是外围这些切碎执行流的细碎开销。
再以 MTP(多 Token 预测)为例,每层引入的额外 LM Head 执行开销或许只有几十微秒。但在 1000 TPS 的高频运行状态下,这几十微秒的权重已经重到足以显著影响系统的端到端效率。
当整个系统需要在微秒级尺度下平稳运行时,纯粹的运行时(Runtime)优化逐渐触及了物理局限。
过去几年,行业的系统优化大多围绕更快的 GEMM、更激进的算子融合以及更复杂的掩盖调度展开。但当系统真正进入超低延迟推理场景后,我们开始频繁遇到一些结构性制约:多级存储架构与模型结构的不匹配、通信拓扑与路由模式的冲突、以及 KV Cache 增长对局部性的破坏。
这些问题的共同点在于,它们会不断制造执行流碎片。
在很多场景下,推理系统已经接近硬件极限,但模型结构本身的某些特性仍会持续产生额外的执行开销。在这一阶段,系统与模型的协同设计(Co-design)开始成为推理走向极限的必然选择。
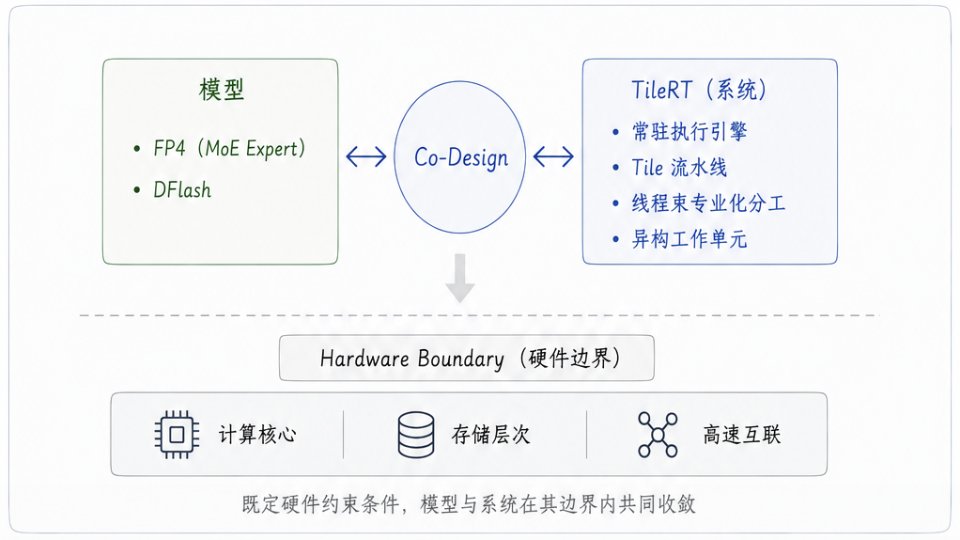
在 TileRT 赋能超大模型生产级落地的过程中,TileRT 系统团队与小米的 MiMo 模型团队展开了深度的技术共创,共同探讨一个核心命题:什么样的模型行为,才真正适合一条超低延迟执行流水线的持续推进?
首先进入优化视野的是 I/O。对于千亿、万亿级的规模模型,带宽压力直接决定了系统的上限。在超低延迟的运行状态下,I/O 成本已经直接进入了延迟的关键路径。为此,TileRT 紧密配合 MiMo 团队的算法特性,在模型层面制定了更具针对性的混合量化策略:仅对 MoE Expert 使用 FP4 量化,其余部分保持 FP8。这并非因为 FP4 概念上“更先进”,而是双方基于硬件物理限制做出的联合工程权衡。
随后,这种深度技术协同进一步延伸到了 DFlash 在生产级系统中的落地。正如前文所述,在极低延迟的高频节拍下,传统 MTP 架构中每一层额外的 LM Head 都会独立产生几十微秒的执行开销。当多层叠加时,这种累积的延迟代价足以显著拖慢整条流水线的端到端效率。
DFlash 的引入为这一瓶颈提供了极具针对性的解法:它在保持高接收率的同时,将 LLM Head 的计算严格收敛。围绕这一算法特性,从 DFlash 的模块结构、滑动窗口大小(sliding window size)、Attention Sink,到接收长度与验证成本(verification cost)的权衡,双方在工程实践中不断剥离微秒级的冗余,最终找到了最优的性能平衡点。
许多过去只属于系统底层的运行时优化难题,开始在模型设计阶段被提前考虑;而模型的骨架,也开始更直接地决定着硬件的实际执行表现。
1000 TPS 的诞生,绝不是某一个孤立优化所能达到的结果。
它更像是一个必然的过程:当执行压力被持续推向硬件的物理边界,模型与系统开始向着彼此深度收敛,最终实现执行范式的一次系统性跃迁。
这套模型与系统协同优化后的成果已经在小米开放平台上线。关于 MiMo-V2.5-Pro-UltraSpeed 的更多技术细节与产品实践,也欢迎阅读小米团队的详细介绍。
速度,正在成为新的 Scaling Law
过去,关于 Scaling Law 的讨论大多集中在参数量、数据集与训练算力上。模型能力往往随着规模的扩张而持续提升。
但当推理开始深入到真实世界的应用场景时,另一个规律开始变得愈发明显:速度本身,正在重新定义大模型能力的边界。
在很长一段时间里,推理系统更多被视为一个单纯的“部署与工程实现问题”。模型负责输出能力,系统负责将模型运行起来,二者虽然会互相影响,但整体上依然保持着相对独立的软件边界。
然而,当系统进入超低延迟的运行区间后,这种边界开始变得模糊。推理速度不再只是一个单纯的系统指标,它开始直接影响到推理深度、Rollout 预算、交互延迟、智能体响应能力,以及 Test-Time Scaling 的实际效率。许多在理论上可行的算法模型,最终能否在应用端真正成立,越来越取决于底层的执行流水线能否在有限的延迟预算内完成闭环。
也正因如此,底层的推理系统开始更深地反向影响模型本身的演化方向。
过去几年,行业更关注 Model Scaling(模型规模化);但未来,另一个方向可能会变得同等重要:Speed Scaling(速度规模化)。
因为当系统性能逼近硬件的物理边界时,任何单一层级的独立演化都将面临瓶颈。微秒级的执行压力,正在推动模型结构、编译器、运行时系统与硬件架构走向深度的协同。整个系统栈需要打破原有的层级藩篱,实现全局的协同设计。
从这个角度来看,1000 TPS 的实现,本质上不仅是一个 Benchmark 的里程碑。
它更像整个大模型推理系统在追求极致速度时,执行范式发生变化的一次提前预演。当系统进入超低延迟状态后,传统的软件分层和抽象将被重新审视,模型与系统共同演化的全新技术范式正在加速到来。
TileRT 在推理执行基础设施侧的这次系统性尝试,正是为了迎接 Speed Scaling 时代的必然演进。而小米的 MiMo 团队,则是较早与我们一同跨入这一全新执行范式的模型同行者。
The speed is all you need.
合作交流
TileRT 团队将持续在高性能 AI 系统的底层构建与极限进行探索,我们也非常欢迎大模型团队和 AI 应用团队和我们深度合作。
如果你对 GPU 架构、编译优化、分布式或大规模推理系统有兴趣,也欢迎加入我们。
- 开源代码库(部分模块): github.com/tile-ai/TileRT
- 交流或简历: contact@tilert.ai