In recent years, the optimization of Large Language Model (LLM) inference systems has revolved almost entirely around three pillars: kernels, operators, and scheduling. A collective path dependency has formed across the industry—the belief that as long as we squeeze every ounce of performance out of a kernel and push FLOPs utilization to its absolute limit, the system will naturally approach the theoretical boundaries of the hardware.
For a long time, this logic was ironclad. The baseline bottleneck of system performance was dominated by “pure, brute-force computation.”
Execution overheads stemming from host launches, hardware synchronizations, runtime scheduling, and global memory transactions certainly existed, but they were naturally masked by dense, heavy compute blocks.
However, as inference enters the battlefield of ultra-low latency, the rules of the game have changed.
The proliferation of autonomous Agents, real-time code completion, voice interaction, and Test-Time Scaling is aggressively driving the infrastructure toward a latency-first era. Users are no longer just looking at aggregate throughput; they are counting every millisecond of responsiveness. When inference speed directly dictates the rollout budget, search depth, and overall quality of agentic interactions, those underlying execution overheads—once safely hidden behind massive compute cycles—are suddenly exposed on the critical path.
Against this backdrop, scaling the performance of flagship models from dozens of Tokens Per Second (TPS) to over 1000 TPS is not a mere linear improvement. It represents a fundamental departure from traditional optimization paradigms.
Dozens of TPS versus 1000+ TPS operate under entirely different dimensions of hardware reality.
The First Leap: The Execution Model Revolution
When we profile down to the bare metal, we find that the true bottleneck throttling performance is not that any single kernel runs too slowly. Rather, it is that the entire execution stream is constantly fractured at the microsecond scale by disjointed operator boundaries.
In traditional inference frameworks, a model is decomposed into a vast collection of isolated operators. Every single kernel launch carries inherent costs: Host-side launch latency, hardware synchronization, and round-trips to Global Memory. Under old compute-bound scenarios, these fixed costs were marginal. But when the system pushes for ultra-low latency—squeezing every microsecond out of a single Token—these gaps, once hidden, manifest as a glaring Execution Gap.
TileRT was architected from day one to eliminate these execution gaps born from operator boundaries.
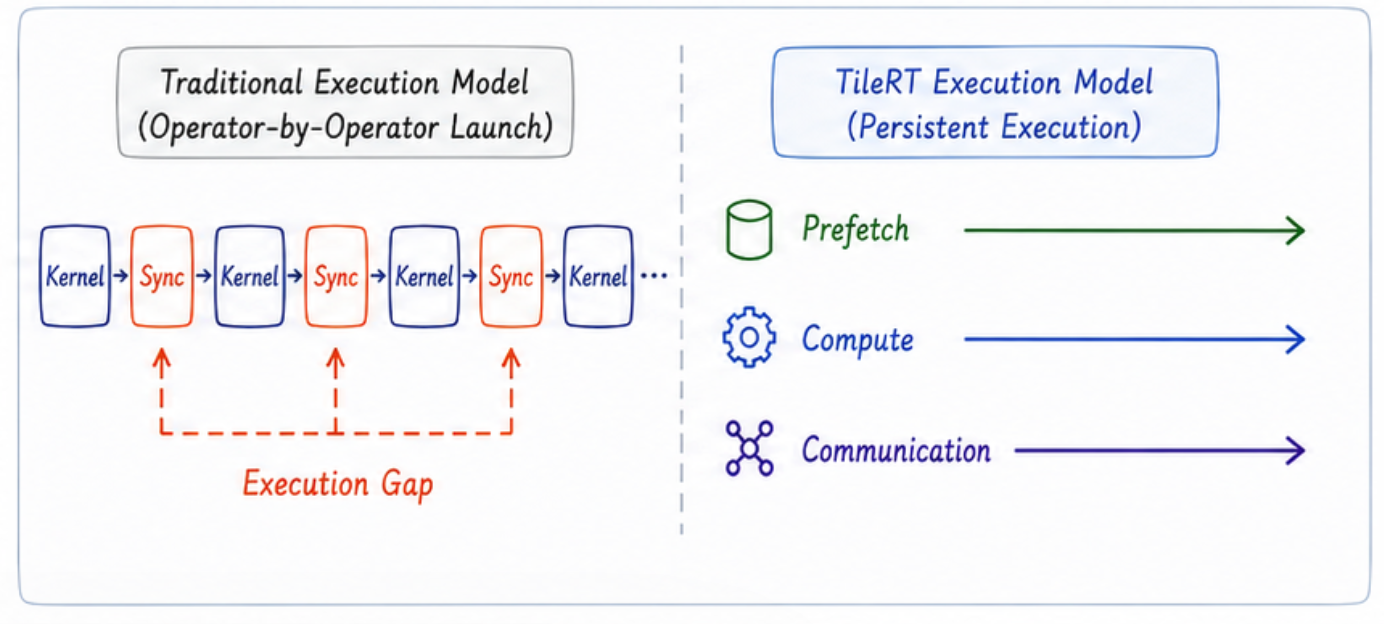
To solve this, we introduced a completely different execution model. Instead of relying on the traditional ‘operator-by-operator launch’ pattern on the GPU, the entire computational pipeline is consolidated into a single, cohesive Persistent Engine that runs continuously inside the hardware.
The core benefit of this persistent paradigm is that it unlocks an end-to-end continuous prefetching capability. While a current Tile is actively processing inside the Compute Cores, subsequent data has already begun flowing ahead of time through the multi-level memory hierarchy—from Global Memory and Shared Memory straight into the registers.
Our Tile-level pipelining further dissects data movement, tensor computation, and communication into finer-grained physical Tiles, achieving much deeper overlap within the silicon.
Within this pipeline, Warp Specialization shatters the old rigid, serial execution pace, assigning dedicated Warp groups to distinct, coordinated roles. The introduction of Heterogeneous Workers then scales this specialization strategy beyond a single Streaming Multiprocessor (SM), extending it across the GPU’s entire execution domain.
Consequently, the GPU evolves from a traditionally homogenous parallel compute device into a continuously flowing, tightly orchestrated, heterogeneous execution system.
This is where the system transcends the boundaries of legacy execution abstractions. The leap from dozens of TPS to hundreds of TPS is not achieved by local optimizations of standalone kernels; it is powered by a fundamental paradigm shift in the execution model itself.
The Second Leap: Breaking the 1000 TPS Barrier
Microsecond-Scale Bottleneck Triage and Hardware-Software Co-Design
Reconstructing the execution model allows us to cross the first order-of-magnitude boundary, climbing from dozens to hundreds of TPS. For flagship models, this already means the system is rapidly encroaching upon the physical limits of the hardware.
But the real engineering cliff lies here: When a system is already sitting on top of the hardware ceiling, how do you double performance again to break 1000 TPS?
In this extreme performance regime, execution bottlenecks expose themselves in entirely new ways.
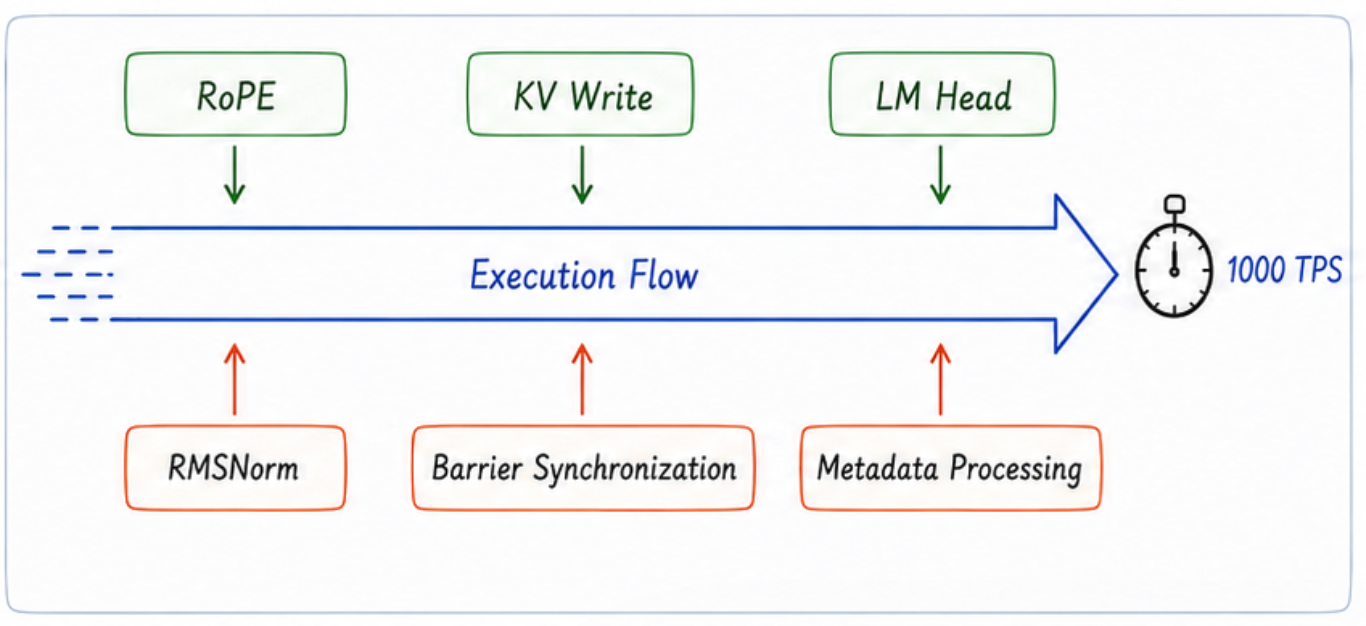
At dozens of TPS, whether an operator runs 1 microsecond faster or slower rarely impacts end-to-end latency, because the timeline is dominated by coarser-grained computation and scheduling. However, once the system enters the 1000+ TPS territory, the lifespan of an individual operator is compressed down to microseconds. At this frequency, a single microsecond of overhead translates directly into percentage points of end-to-end performance jitter. Many seemingly trivial, non-core operators suddenly resurface as devastating bottlenecks.
Operations like RMSNorm, RoPE, KV Cache writes, hardware syncs, and metadata overhead fall into this category. Individually, their FLOP count is negligible, but on a microsecond clock, they repeatedly fracture the execution stream, aggregating into severe latency penalties. In the Attention layer, for instance, the ultimate throttle is often no longer the Attention kernel itself, but these fragmented auxiliary operations surrounding it.
Take Multi-Token Prediction (MTP) as another example. The extra LM Head execution per layer might only introduce dozens of microseconds. Yet, under a high-frequency 1000 TPS regime, the weight of these dozens of microseconds becomes heavy enough to severely drag down end-to-end efficiency.
When an entire system must run smoothly at a microsecond cadence, pure runtime-level optimizations hit a physical wall.
For years, system optimization in the industry has targeted faster GEMMs, more aggressive fusion, and sophisticated hiding strategies. But in ultra-low latency inference, we inevitably collide with structural constraints: mismatches between multi-level memory hierarchies and model architectures, conflicts between communication topologies and routing patterns, and the destruction of data locality caused by KV Cache growth.
The common denominator of these issues is that they continuously generate execution fragments.
In many scenarios, while the inference system has pushed the hardware to its absolute limit, intrinsic properties of the model architecture continue to inject redundant execution overhead. At this stage, Hardware-Software Co-design (System-Model Co-design) becomes the only viable path to transcend the hardware ceiling.
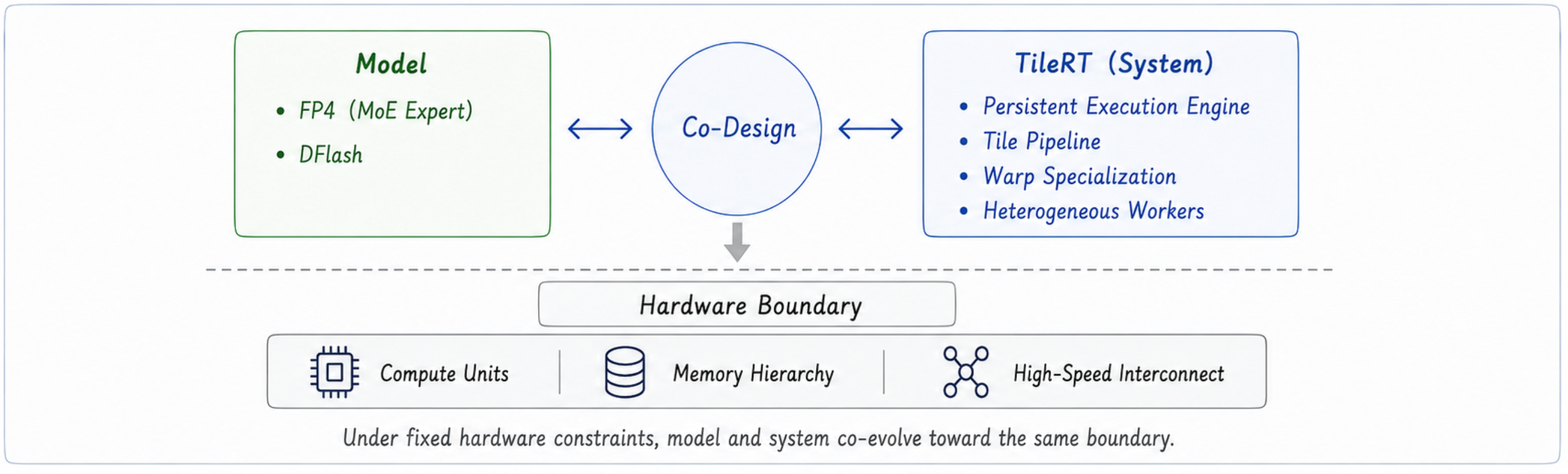
To bring ultra-large models into production-ready deployment, the TileRT systems team embarked on a deep technical co-creation with Xiaomi’s MiMo model team. Together, we attacked a core proposition: What kind of model architecture and behavior is fundamentally suited to sustain an ultra-low-latency, continuous execution pipeline?
First came the optimization of I/O. For 100B or 1T-plus parameter models, memory bandwidth directly dictates the system ceiling. Under ultra-low latency execution, I/O costs sit squarely on the critical path. To address this, TileRT tightly aligned with the algorithmic traits of the MiMo team to implement a highly targeted, mixed-precision quantization strategy: FP4 quantization is applied exclusively to the MoE Experts, while the rest of the network maintains FP8. This was not because FP4 is conceptually “fancier,” but because it was a deliberate, joint engineering trade-off calculated based on hardware physical boundaries.
This deep technical synergy extended further into the production-grade deployment of DFlash. As noted earlier, under ultra-low latency cadences, each additional LM Head in traditional MTP architectures independently incurs dozens of microseconds of execution overhead. Layered together, this accumulated latency significantly slows down the end-to-end pipeline.
The integration of DFlash provided a highly tailored solution to this bottleneck: it maintains a high acceptance rate while strictly converging the compute footprint of the LLM Head. Centered around this algorithmic trait, both teams meticulously stripped away microsecond-level redundancies—balancing everything from DFlash module structures, sliding window sizes, and Attention Sinks, to acceptance lengths versus verification costs—ultimately striking the optimal performance equilibrium.
Consequentially, system-level runtime challenges that once belonged exclusively to low-level engineering are now anticipated during the model design phase, while the structural skeleton of the model increasingly determines the actual execution efficiency of the hardware.
The birth of 1000+ TPS is never the result of an isolated patch or single optimization. It is an inevitable convergence: when execution pressure is relentlessly pushed against physical limits, the model and the system must deeply converge, culminating in a systemic leap of the execution paradigm.
The result of this model–system co-design has already been deployed on Xiaomi's open platform. For more technical details and product insights behind MiMo-V2.5-Pro-UltraSpeed, we invite readers to explore Xiaomi's official technical write-up.
Speed is the New Scaling Law
Historically, discussions around the Scaling Law have centered on parameter sizes, dataset tokens, and training compute. Model capabilities scaled predictably alongside compute expenditures.
But as inference penetrates deeply into real-world applications, another law is becoming undeniably clear: Speed itself is redefining the boundaries of model capability.
For the longest time, inference systems were viewed merely as a “deployment and engineering implementation detail.” The model supplied the capability; the system simply ran it. While they influenced one another, they maintained distinct, independent software abstractions.
However, as systems enter ultra-low latency regimes, these boundaries blur. Inference speed is no longer just a raw infrastructure metric. It directly dictates inference depth, rollout budgets, interactive latency, agentic autonomy, and the actual viability of Test-Time Scaling. Many algorithms that are brilliant in theory can only succeed in production if the underlying execution pipeline can close the loop within a razor-thin latency budget.
Because of this, the underlying inference system has begun to deeply dictate the evolutionary direction of the model architecture itself.
The past era focused heavily on Model Scaling; the upcoming era will place equal weight on Speed Scaling.
When system performance edges closer to physical hardware boundaries, independent evolution at any single layer hits a point of diminishing returns. Microsecond-level execution pressure forces model architectures, compilers, runtimes, and hardware topologies into deep synchronization. The entire system stack must break down traditional silos to achieve global co-design.
From this perspective, achieving 1000+ TPS is more than a benchmark milestone.
It serves as an early rehearsal for the paradigm shift that occurs when an entire LLM inference stack chases absolute speed. As systems enter an ultra-low latency state, traditional software layers and abstractions will be fundamentally re-examined, accelerating the arrival of a new technical paradigm where models and systems evolve as one.
TileRT’s systemic overhaul of inference execution infrastructure is built precisely to welcome this era of Speed Scaling. And Xiaomi’s MiMo team stands among the earliest model pioneers to cross into this new execution paradigm alongside us.
Speed is all you need.
Connect With Us
The TileRT team will continuously explore the bare metal of high-performance AI systems and push the absolute limits of execution infrastructure. We warmly welcome deep collaborations with LLM pre-training/inference teams and AI application developers.
If you are passionate about GPU architectures, compiler optimizations, distributed computing, or ultra-large-scale inference systems, we invite you to join us.
- Open-Source Repository (Select Modules): github.com/tile-ai/TileRT
- Inquiries & Resumes: contact@tilert.ai